关于一些Pipeline开发分享
关于一些Pipeline开发分享
lingyun引言
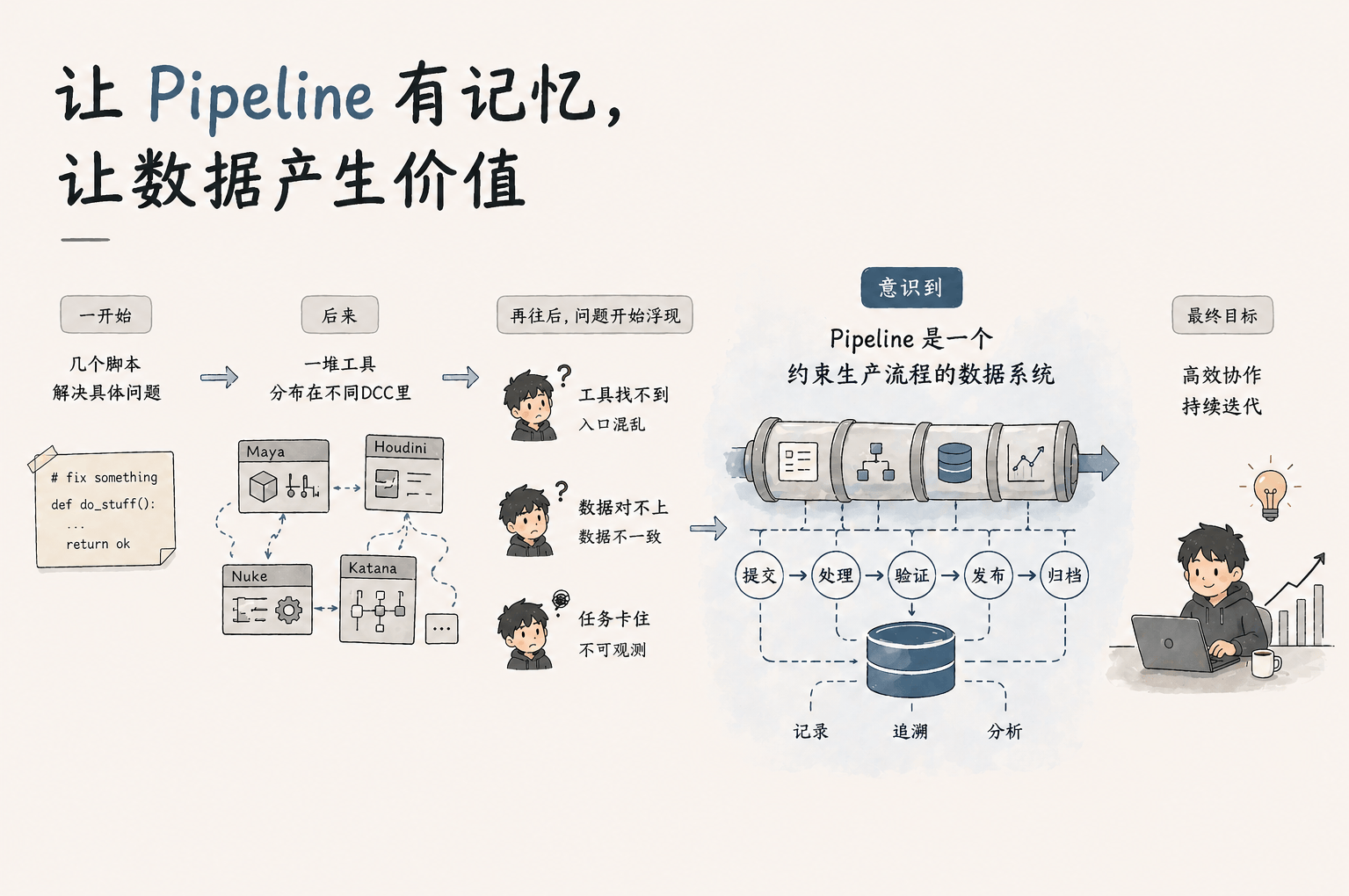
在大多数VFX团队中,Pipeline并不是被设计出来的,而是“逐渐长出来的”。
一开始,只是几个脚本,用来解决具体问题;
后来变成一堆工具,分布在不同DCC里。
再往后,问题开始浮现
- 之前用过一个工具怎么找不到了:工具入口混乱
- 为什么发布后的缓存跟我拍屏对不上:数据不一致
- 发布任务卡着不动,不知道是否“死”掉了:任务可观测性缺失
这时候意识到问题:
Pipeline并不是工具集合,而是一个“约束生产流程的数据系统”。
但这些认知,并不是一开始就想清楚的,而是在一次次具体问题中被“逼”出来的。
这篇文章是结合一些实际开发中的问题和解决方式,分享在Pipeline演进过程中的一些经验。
基建: TD也需要自己的Pipeline
我们习惯为制作人员设计Pipeline,但很少有人认真思考一件事:
TD团队本身,也需要一套自己的Pipeline。
记得刚转到开发岗时,我的主管就是一位专门开发 Core Pipeline 的TD。
他并不直接写面向Artist的工具,而是为我们这些TD提供“基础能力”,定义TD应该如何工作。
并把这种工作方式工具化、标准化。
将工作流工具化
当时团队里有一套工具,它基于 GitLab Flow,通过一组命令行,把整个开发工作流串了起来。
当我们接到一个需求时,不是手动去找项目、拉代码、建分支、开IDE。
而是执行:
1 | pipe setup |
工具会进入一个问询式对话:
1 | 请输入 Jira 工单号: |
然后它会自动完成:
1 | 初始化本地 workspace |
在开发的过程中可以
1 | pipe check # 调用 ruff 检查代码规范 |
这些命令看起来只是简化了日常操作,但它真正解决的,是把一整套开发流程变成了“默认行为”。
从需求认领、环境初始化,到代码检查、测试环境创建,
每一步都不再依赖个人习惯,而是由工具统一约束。
标准化通用函数
一个常见需求,通过当前文件路径找到当前任务是什么,并获取任务id。
如果不提供标准方法,通常是:
自己解析路径、手动拼规则、再去调用 Shotgun 查询,每个人都有自己的一套实现方式。
这样一来,一旦底层规则发生变化,每个人都需要去修改各自的代码来适配。
对这样的需求可以实现一个通用函数供大家调用
1 | from pipeline.core import get_context_from_path |
除此之外,对于日常频繁打交道的系统,比如 Shotgun、Deadline,
我们也可以在它们之上再封装一层,作为 TD 自己的工具。
示例:
1 | import sgi # Shotgun模块封装 |
有了这些标准化的通用方法,每个TD不再需要关心“规则是如何实现的”,
只需要直接使用“规则本身”。
可配置的Pipeline
记得有一次,下班刚背上包准备走,制作同事跑过来说检查项过不去。
但这个文件因为一些特殊原因,需要临时跳过某个检查项。
问题在于,我们的检查规则是写死在代码里的。
如果要调整,只能走一遍完整的代码发布流程。
而且这还只是一个镜头的临时需求:
我需要为它“开一次口子”,等它发布完,还得再把代码改回去。
很多检查项是放在yaml/json文件里,这些都是随Git部署在服务中,没法灵活修改。
后来开始尝试把这些配置从代码中抽离出来,托管到数据库中。

有了这一次尝试,会发现:
不只是检查项,Pipeline中其实有大量“适合被配置化”的内容。
比如DCC的启动配置,每个工具的启动,本质上都是一条命令:
- Maya2023:
rez-env maya-2023 maya_extend mtoa -- maya - Houdini20.5:
rez-env houdini-20.5 houdini_extend htoa -- hfs - xxTool:
rez-env xxtool -- run
还可用作全局控制开关
- 是否允许Publish:当存储服务器出现问题,暂时关闭发布入口。
- 是否允许提交Deadline:当Deadline升级时,暂时关闭提交入口。
- 某个模块的版本:指定版本/latest
- …
工具体验的一致性与效率优化
统一UI风格
当用户打开不同工具时,如果每个界面风格、交互方式都不一致,
就意味着他们每次都要重新学习一遍。
因此,我们会尽量统一:
- 界面布局(标题/简单说明/帮助文档跳转按钮)
- 状态反馈(成功 / 失败 / 过程提示)
我自己常用的工具布局大概是这样:
然后基于这个布局,抽象出一个 CommonToolDialog 基类。
封装一些通用能力,之后开发的每个工具,只需要继承这个基类,
专注实现自己的业务逻辑,而不需要重复搭建 UI。
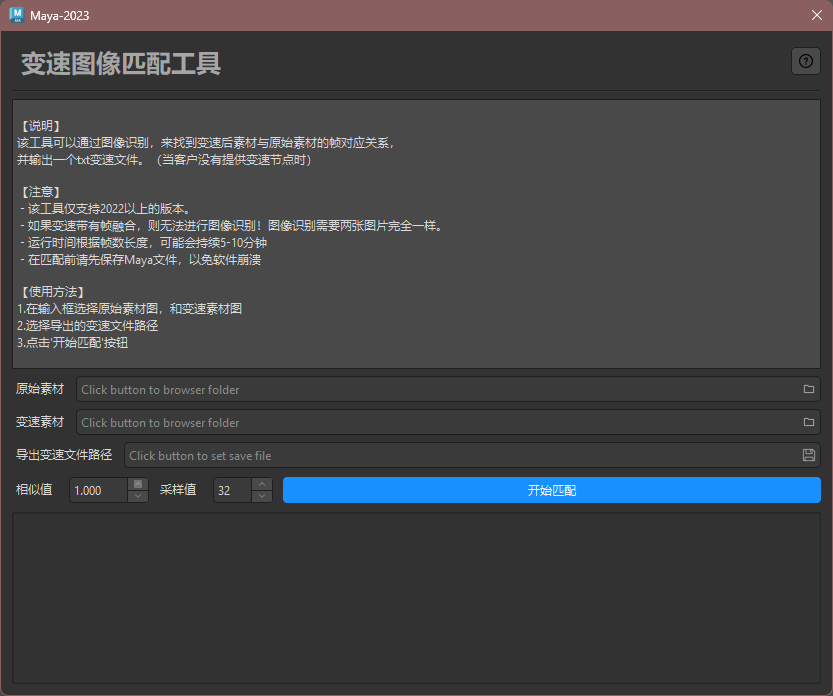
这样用户也会逐渐形成稳定的使用习惯,工具之间的差异被降低,使用成本也随之降低,
最终形成一套无需说明即可上手的使用体验。
工具入口
不少公司的工具还是习惯被集中放置在软件菜单中。
但随着数量不断增加,菜单层级变深、条目变多,用户在查找某个工具时需要逐项扫视,效率较低。
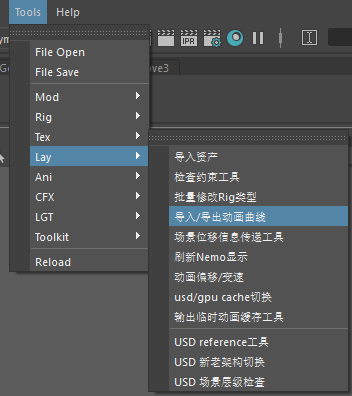
后来我们转向使用“工具库”的形式,提供了分类,搜索,收藏等功能。
通过快捷键打开工具面板(吸附在侧边栏),默认焦点放在搜索栏,
输入关键字就可以快速定位到要使用工具。
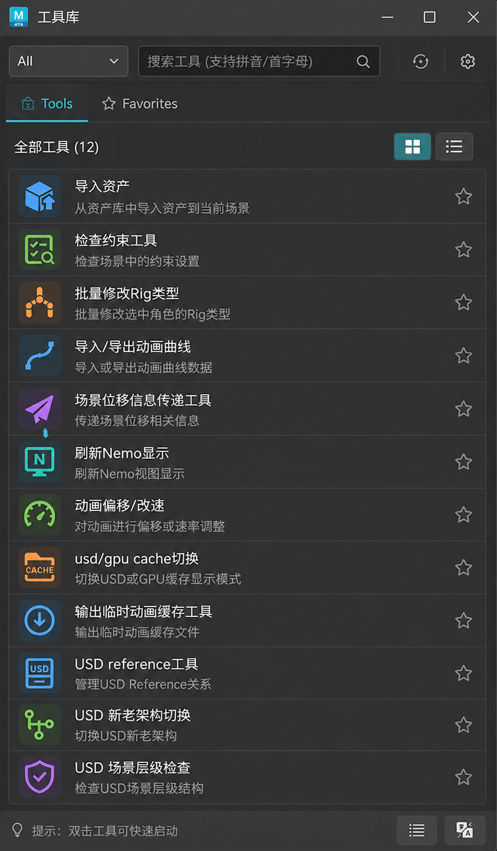
(图片由AI生成)
对这样的工具库我们还可以做一些优化,比如使用类似Quick Launcher聚焦搜索来简化调用方式
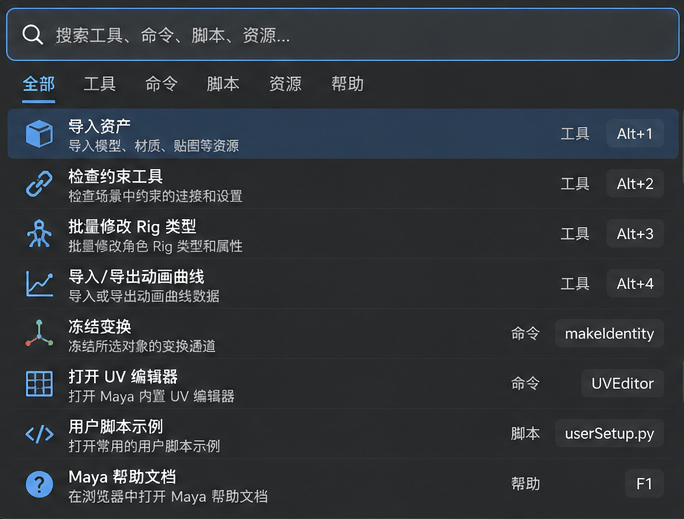
(图片由AI生成)
甚至也可以使用AI为它进行赋能,为每个工具写一份metadata定义,当用户询问“我要将动画导出到别的镜头”,
工具库就会按照相似度排序,在搜索结果在显示满足需要的工具。
(这真的很有必要,公司人员总是在流动,常常会被问到”我们有xxx工具吗?” )
速度优化
在之前一家公司,我们使用的是Shotgun提供的集成框架Toolkit。
自然就会用到SG流程三件套: Loader,Publisher,Workfiles。
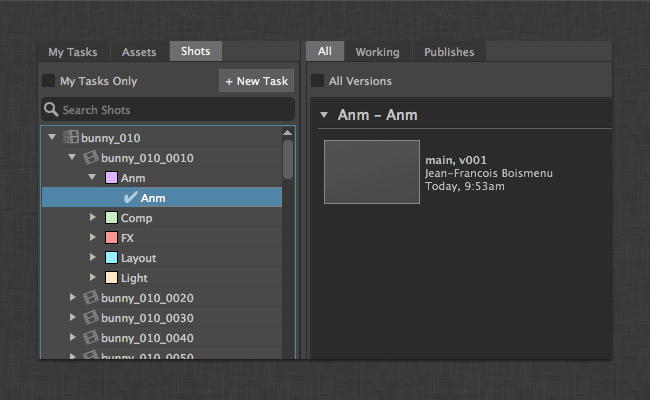
这些工具本身提供了完整的流程能力,但由于 ShotGrid 采用远程服务的方式,
每次打开工具通常需要 2-3 秒,在网络不稳定的情况下甚至会出现卡顿或无响应。
一开始大家还能接受,但随着使用频率增加,这种“每次都要等一下”的体验会被不断放大,
最终带来的结果是:制作人员逐渐放弃使用工具,转而采用手动操作。
但问题在于,Pipeline 中的很多操作其实并不是“简单操作”。
例如一个看似简单的“导入资产”,在工具内部往往包含了多步逻辑:
- 创建规范的层级结构
- 绑定正确的资产路径
- 写入自定义属性
- 锁定关键节点,防止误操作
当用户绕过工具,直接手动导入时,这些隐含的流程约束就会全部丢失,
从而带来数据不规范、流程不可控等一系列问题。
当时的解决方式是: 抛弃掉SG提供的app,自己开发三件套。
写完后发现打开速度是比之前快不少,但获取SG数据本身还是使用shotgun_api3请求远程数据库,
在获取Task或Version数据时还是会有1-2秒的“卡顿”。
后来在网上翻到了“把SG数据缓存到本地数据库”的方案。
核心做法是
- 1.建表: 根据 Shotgun schema 在 PostgreSQL 中自动创建所有实体对应的表和字段
- 2.全量同步SG数据到数据库
- 3.使用 Shotgun event daemon 监听事件变更同步
- 4.提供一个查询缓存的接口
改造完成后,用户体验有了明显提升,整个使用过程从“每一步都要等一下”,变成了几乎无感的实时交互。
在开发过程中,把自己想象成使用者
如何让使用者不排斥工具,愿意主动使用;
让用户能快速找到工具;
降低学习成本,让新工具能够被快速理解和上手;这些都是在设计和开发过程中持续思考的问题。
数据留存
为了让 Pipeline 具备可追溯性和可分析能力,我们在各个关键环节尽量记录更多数据。
发布数据增强
之前遇到过一个典型问题:
由于检查逻辑不完善,导致部分模型的绑定关系与点序不匹配。
作为 TD,需要快速筛出所有存在问题的资产。但当资产规模达到上百个时,
如果逐个打开文件、读取点序再进行比对,这种方式显然是低效的。
当时想着,如果能在发布时,将关键结构信息(例如点序、面数等)写入一个结构化文件(如 YAML),
从而将原本需要逐个打开文件的操作,转化为对文本数据的快速比对,这个文件可以像是:
1 | asset: |
所以在发布阶段,不仅仅是输出文件,尽量记录更多上下文信息,能对我们的排错工作提供很大帮助。
历史记录
运行过程中的日志非常重要,它不仅用于排错,更用于溯源。
因为大多数情况下,当问题被发现时,已经是一个“结果状态”:
文件已经生成、场景已经被修改,问题已经发生。
一个典型场景:
当你发现文件中的某个资产缺少关键属性时,
很容易怀疑是制作过程中没有正确使用工具进行引用。
但制作人员往往会说:
“我就是按流程操作的,也不知道为什么会变成这样。”
这个时候,问题就变成了一个悬案。
- 工具是否被正确使用?
- 使用时传入了什么参数?
- 中间是否有异常或被中断?
- 是否有人手动修改了结果?
有日志就像是监控,当问题发生时,我们不再依赖人的记忆,而是依赖数据本身。
使用统计
这源于某天的好奇,我们开发了这么多工具,制作都在用吗?什么是他们常用的?
这其实对于我做一些判断非常有用,实现起来也不难,写个装饰器,记到数据库里就行。
最后
为什么要写这一篇?因为最近在维护一个比较老的流程,
在修修补补的过程中,会不断想起以前做过的一些好的方案。
在现在的动画影视行业里,留给 TD 配额其实不多,
一个人往往要同时负责好几个环节。
大多数时间,我们都在做“修补”。
很多问题其实心里很清楚根源在哪,
但现实里,很难真的从底层去改掉它。
所以就先把这些经验记录下来,分享出来。
也希望这个行业,能慢慢变得好一点。